
PythonでディープラーニングなどでAIによる処理を実現する際やデータ分析を行う時に必ずといっていいほど使うのがNumpyライブラリです。
本記事では、Numpyの基本的な使い方についてご紹介します。
まずはndarray型のデータの準備から
Numpyを使うためには最初にndarray型というデータ型を用意する必要があります。ndarray型のデータに似たものとしてリストがありますが、リストのままではNumpyを使うことができません。
そこで、一度リストを用意した後ndarray型にデータ型を変更します。
リストを作成し、それを引数としてarrayメソッドの引数に渡すだけでndarray型のNumpy配列が作成できます。
import numpy as np
list_1d = [1,2,3,4,5]
array_1d = np.array(list_a)
print(list_1d)
print(array_1d)list_1dというNumpy配列を作り、それをnp.arrayの引数に渡しました。
それぞれを表示するとこのようになります。
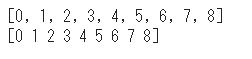
仕様の違いで見た目に若干の違いがありますが、一次元の配列であることが分かります。
type()でそれぞれの配列のデータ型がリストとndarray型になっていることも確認できます。
type(list_1d)
type(array_1d)
Numpy shape
リストの名前の後ろに.shapeを付けるとそのNumpy配列の次元ごとの要素数を取得できます。
print(array_1d.shape)
array_aの次元は一次元で要素数が9個なので、(9,)となります。
Numpy reshape
先ほどの例は一次元でしたが、二次元のリストならどうなるでしょうか?
まずは、先ほど作成したarray_aの次元数を一次元から二次元に変更します。今回は要素数が9個ということで、3×3の二次元の形に変更してみます。
Numpy配列は、reshape()メソッドで次元数を変更できます。
array_2d = array_1d.reshape(3,3)
print(array_2d)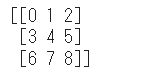
やや分かりにくいかもしれないですが、[0, 1, 2, 3, 4, 5, 6, 7, 8]という横並びだったNumpy配列が[0, 1, 2, 3]と[3, 4, 5]と[6, 7, 8]という三つの要素を縦に並べたような行列になったことがイメージできます。
この二次元のNumpy配列の次元数ごとの要素数はshape()でこのように表示されます。
print(array_2d.shape)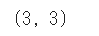
一次元の時と比べると表示される数字が2つとなり、二次元であることが分かります。また、それぞれの要素数が3と3であることも分かります。
Numpyを使った配列の四則演算
Numpy配列は+や-などの四則演算を全ての要素または要素に対して実行できます。
例として、すべての要素に5を足します。
array_a = array_2d + 5
print(array_a)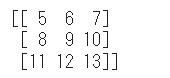
配列同士の演算も可能です。3×3のNumpy配列同士を足してみます。
array_b = array_2d + array_a
print(array_b)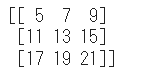
特定の要素に四則演算を行う
特定の要素に四則演算を行う方法は幾つか考えられますが、その内の一つが0や1の要素を持つNumpy配列を用いる方法です。
今回はarray_2dの要素の内、0列目(左端の列)だけに4をかけてみます。
array_b = array_2d * np.array([4,1,1])
print(array_b)0列目以外の列に1を配置したNumpy配列を掛けることで特定の要素だけに4をかけています。
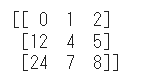
ところで、上記の計算では3×3のNumpy配列に対して1行×3列のNumpy配列を掛けました。
普通の行列計算なら計算不可なんですが、計算ができたのはNumpyのブロードキャストのおかげです。つまり、足りない要素を埋め合わせてくれる機能が備わっています。

